Filtering signal in azimuthal space#
Usually, diffraction signal presents a polar symmetry, this means all pixels with the same azimuthal angle (χ) have similar intensities. The best way to exploit this is to take the mean, what is called azimuthal average. But the average is very sensitive to outliers, like gaps, missing pixels, shadows, cosmic rays or reflections coming from larger crystallites. In this tutorial we will see two alternative ways to remove those unwanted signals and focus on the majority of pixels: sigma clipping and median filtering.
import os
import time
os.environ["PYOPENCL_COMPILER_OUTPUT"]="0"
import pyFAI
print(f"pyFAI version: {pyFAI.version}")
pyFAI version: 2026.6.0-dev0
%matplotlib inline
from matplotlib.pyplot import subplots
from pyFAI.gui import jupyter
import numpy, fabio, pyFAI
from pyFAI import benchmark
from pyFAI.test.utilstest import UtilsTest
figsize = (10,5)
ai = pyFAI.load(UtilsTest.getimage("Pilatus6M.poni"))
img = fabio.open(UtilsTest.getimage("Pilatus6M.cbf")).data
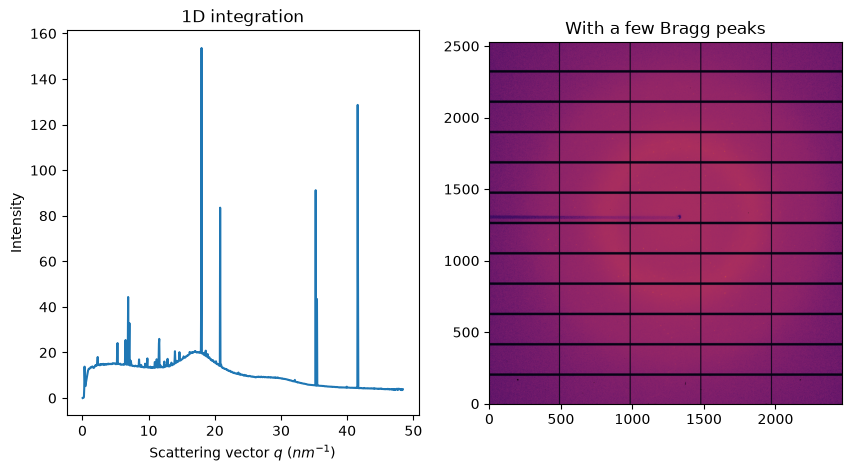
fig, ax = subplots(1, 2, figsize=figsize)
jupyter.display(img, ax=ax[1])
jupyter.plot1d(ai.integrate1d(img, 1000), ax=ax[0])
ax[1].set_title("With a few Bragg peaks");
WARNING:pyFAI.gui.matplotlib:Matplotlib already loaded with backend `inline`, setting its backend to `QtAgg` may not work!
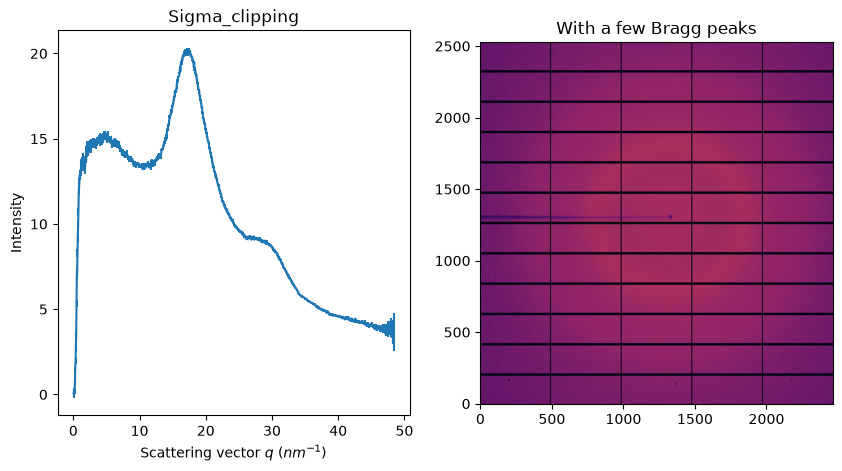
Azimuthal sigma-clipping#
The idea is to discard pixels which look like outliers in the distribution of all pixels contributing to a single azimuthal bin. It requires an error model like poisson but it has been proven to be better to use the variance in the given azimuthal ring. All details are available in this publication: https://doi.org/10.1107/S1600576724011038 also available at https://doi.org/10.48550/arXiv.2411.09515
fig, ax = subplots(1, 2, figsize=figsize)
jupyter.display(img, ax=ax[1])
jupyter.plot1d(ai.sigma_clip(img, 1000, error_model="hybrid", method=("no", "csr", "cython")), ax=ax[0])
ax[1].set_title("With a few Bragg peaks")
ax[0].set_title("Sigma_clipping");
Of course, sigma-clip takes several extra parameters like the number of iterations to perform, the cut-off, the error model, … There are also a few limitations:
The algorithm needs to be the CSR-sparse matrix multiplication: since several integrations are needed, it makes no sense to use a histogram based algorithm.
The algorithm is available with any implementation: Python (using scipy.saprse), Cython and OpenCL, and it runs just fine on GPU.
Sigma-clipping is incompatible with any kind of pixel splitting: With pixel splitting, a single pixel can contribute to several azimuthal bins and discarding a pixel in one ring could disable it in the neighboring ring (or not, since bins are processed in parallel).
Sigma-clipping performances:#
method = ["no", "csr", "cython"]
%%time
perfs_integrate_python = {}
perfs_integrate_cython = {}
perfs_integrate_opencl = {}
perfs_sigma_clip_python = {}
perfs_sigma_clip_cython = {}
perfs_sigma_clip_opencl = {}
for ds in pyFAI.benchmark.PONIS:
ai = pyFAI.load(UtilsTest.getimage(ds))
if ai.wavelength is None: ai.wavelength=1.54e-10
img = fabio.open(UtilsTest.getimage(pyFAI.benchmark.datasets[ds])).data
size = numpy.prod(ai.detector.shape)
print(ds)
print(" Cython")
meth = tuple(method)
nbin = max(ai.detector.shape)
print(" * integrate ", end="")
perfs_integrate_cython[size] = %timeit -o ai.integrate1d(img, nbin, method=meth)
print(" * sigma-clip", end="")
perfs_sigma_clip_cython[size] = %timeit -o ai.sigma_clip(img, nbin, method=meth, error_model="azimuthal")
print(" Python")
meth = tuple(method[:2]+["python"])
print(" * integrate ", end="")
perfs_integrate_python[size] = %timeit -o ai.integrate1d(img, nbin, method=meth)
print(" * sigma-clip", end="")
perfs_sigma_clip_python[size] = %timeit -o ai.sigma_clip(img, nbin, method=meth, error_model="azimuthal")
print(" OpenCL")
meth = tuple(method[:2]+["opencl"])
print(" * integrate ", end="")
perfs_integrate_opencl[size] = %timeit -o ai.integrate1d(img, nbin, method=meth)
print(" * sigma-clip", end="")
perfs_sigma_clip_opencl[size] = %timeit -o ai.sigma_clip(img, nbin, method=meth, error_model="azimuthal")
Pilatus1M.poni
Cython
* integrate
18.8 ms ± 2.13 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
* sigma-clip
17.2 ms ± 1.73 ms per loop (mean ± std. dev. of 7 runs, 100 loops each)
Python
* integrate
10 ms ± 78.1 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
* sigma-clip
159 ms ± 628 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
OpenCL
* integrate
698 μs ± 1.13 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
* sigma-clip
2.46 ms ± 10 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Pilatus2M.poni
Cython
* integrate
29.1 ms ± 3.49 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
* sigma-clip
27.4 ms ± 565 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Python
* integrate
34.5 ms ± 430 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
* sigma-clip
543 ms ± 1.32 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
OpenCL
* integrate
1.11 ms ± 2.25 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
* sigma-clip
5.98 ms ± 24.4 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Eiger4M.poni
Cython
* integrate
37.8 ms ± 3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
* sigma-clip
35.9 ms ± 485 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Python
* integrate
61.4 ms ± 168 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
* sigma-clip
1.12 s ± 1.41 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
OpenCL
* integrate
2.15 ms ± 8.84 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
* sigma-clip
10.7 ms ± 12 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Pilatus6M.poni
Cython
* integrate
49.5 ms ± 3.55 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
* sigma-clip
43.8 ms ± 969 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Python
* integrate
83 ms ± 240 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
* sigma-clip
1.54 s ± 6.25 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
OpenCL
* integrate
3.04 ms ± 8.5 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
* sigma-clip
13.9 ms ± 53.4 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Eiger9M.poni
Cython
* integrate
69.7 ms ± 4.15 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
* sigma-clip
68.4 ms ± 2.45 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
Python
* integrate
151 ms ± 294 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
* sigma-clip
3.06 s ± 4.02 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
OpenCL
* integrate
4.63 ms ± 7.27 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
* sigma-clip
25.7 ms ± 39.1 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Mar3450.poni
Cython
* integrate
71.4 ms ± 5.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
* sigma-clip
70.8 ms ± 4.01 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
Python
* integrate
164 ms ± 545 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
* sigma-clip
3.39 s ± 4.46 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
OpenCL
* integrate
5.2 ms ± 11.8 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
* sigma-clip
28.6 ms ± 47.9 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Fairchild.poni
Cython
* integrate
110 ms ± 2.45 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
* sigma-clip
129 ms ± 3.19 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
Python
* integrate
380 ms ± 529 μs per loop (mean ± std. dev. of 7 runs, 1 loop each)
* sigma-clip
9.43 s ± 16 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
OpenCL
* integrate
4.86 ms ± 7.63 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
* sigma-clip
33.5 ms ± 45.4 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
CPU times: user 35min 55s, sys: 33.5 s, total: 36min 28s
Wall time: 5min 36s
fig, ax = subplots()
ax.set_xlabel("Image size (Mpix)")
ax.set_ylabel("Frames per seconds")
sizes = numpy.array(list(perfs_integrate_python.keys()))/1e6
ax.plot(sizes, [1/i.best for i in perfs_integrate_python.values()], label="Integrate/Python", color='green', linestyle='dashed', marker='1')
ax.plot(sizes, [1/i.best for i in perfs_integrate_cython.values()], label="Integrate/Cython", color='orange', linestyle='dashed', marker='1')
ax.plot(sizes, [1/i.best for i in perfs_integrate_opencl.values()], label="Integrate/OpenCL", color='blue', linestyle='dashed', marker='1')
ax.plot(sizes, [1/i.best for i in perfs_sigma_clip_python.values()], label="Sigma-clip/Python", color='green', linestyle='dotted', marker='2')
ax.plot(sizes, [1/i.best for i in perfs_sigma_clip_cython.values()], label="Sigma-clip/Cython", color='orange', linestyle='dotted', marker='2')
ax.plot(sizes, [1/i.best for i in perfs_sigma_clip_opencl.values()], label="Sigma-clip/OpenCL", color='blue', linestyle='dotted', marker='2')
ax.set_yscale("log")
ax.legend()
ax.set_title("Performance of Sigma-clipping vs integrate");
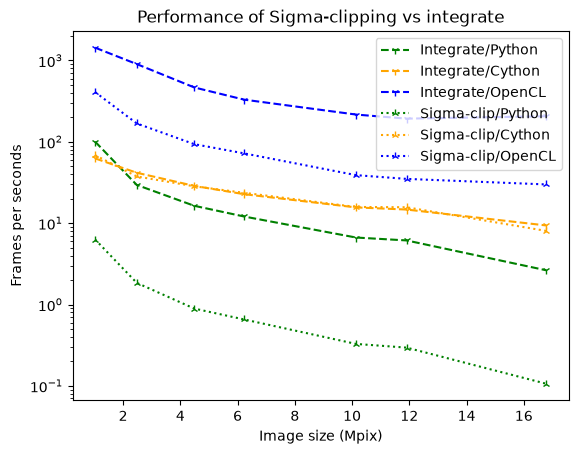
The penalty is very limited in Cython, much more in Python.
The biggest limitation of sigma-clipping is its incompatibility with pixel-splitting, a feature needed when oversampling, i.e. taking many more points than the size of the diagonal of the image. While oversampling is not recommended in the general case (due to the cross-correlation between bins it creates), it can be a necessary evil, especially when performing Rietveld refinement where 5 points per peak are needed, resolution that cannot be obtained with the pixel-size/distance couple accessible by the experimental setup.
Median filter in Azimuthal space#
The idea is to sort all pixels contributing to an azimuthal bin and to average out all pixels between the lower and upper quantile. When those two thresholds are at one half, this filter provides actually the median. In order to be compatible with pixel splitting, each pixel is duplicated as many times as it contributes to different bins. After sorting fragments of pixels according to their normalization corrected signal, the cumulative sum of normalization is performed in order to determine which fragments to average out.
ai = pyFAI.load(UtilsTest.getimage("Pilatus6M.poni"))
img = fabio.open(UtilsTest.getimage("Pilatus6M.cbf")).data
method = ["full", "csr", "cython"]
percentile=(40,60)
pol=0.99
fig, ax = subplots(1, 2, figsize=figsize)
jupyter.display(img, ax=ax[1])
jupyter.plot1d(ai.medfilt1d_ng(img, 1000, method=method, percentile=percentile, polarization_factor=pol), ax=ax[0])
ax[1].set_title("With a few Bragg peaks")
ax[0].set_title("Median filtering");
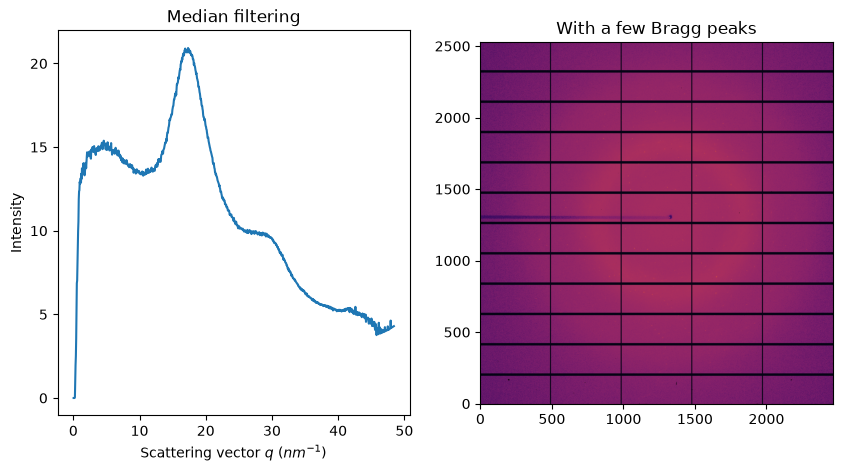
Unlike the sigma-clipping, this median filter does not require any error model; but the computational cost induced by the sort is huge. In addition, the median is very sensitive and requires a good geometry and modelisation of the polarization.
%%time
perf2_integrate_python = {}
perf2_integrate_cython = {}
perf2_integrate_opencl = {}
perf2_medfilt_python = {}
perf2_medfilt_cython = {}
perf2_medfilt_opencl = {}
for ds in pyFAI.benchmark.PONIS:
ai = pyFAI.load(UtilsTest.getimage(ds))
if ai.wavelength is None: ai.wavelength=1.54e-10
img = fabio.open(UtilsTest.getimage(pyFAI.benchmark.datasets[ds])).data
size = numpy.prod(ai.detector.shape)
print(ds)
print(" Cython")
meth = tuple(method)
nbin = max(ai.detector.shape)
print(" * integrate ", end="")
perf2_integrate_cython[size] = %timeit -o ai.integrate1d(img, nbin, method=meth)
print(" * medianfilter", end="")
perf2_medfilt_cython[size] = %timeit -o ai.medfilt1d_ng(img, nbin, method=meth)
print(" Python")
meth = tuple(method[:2]+["python"])
print(" * integrate ", end="")
perf2_integrate_python[size] = %timeit -o ai.integrate1d(img, nbin, method=meth)
print(" * medianfilter", end="")
perf2_medfilt_python[size] = %timeit -o ai.medfilt1d_ng(img, nbin, method=meth)
print(" OpenCL")
meth = tuple(method[:2]+["opencl"])
print(" * integrate ", end="")
perf2_integrate_opencl[size] = %timeit -o ai.integrate1d(img, nbin, method=meth)
print(" * medianfilter", end="")
perf2_medfilt_opencl[size] = %timeit -o ai.medfilt1d_ng(img, nbin, method=meth)
Pilatus1M.poni
Cython
* integrate
21.6 ms ± 1.03 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
* medianfilter
28.7 ms ± 1.84 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
Python
* integrate
13.7 ms ± 124 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
* medianfilter
1.18 s ± 16.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
OpenCL
* integrate
743 μs ± 681 ns per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
* medianfilter
9.42 ms ± 4.59 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Pilatus2M.poni
Cython
* integrate
30.3 ms ± 3.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
* medianfilter
75.4 ms ± 1.93 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
Python
* integrate
45.9 ms ± 217 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
* medianfilter
3.99 s ± 12.8 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
OpenCL
* integrate
1.25 ms ± 7.93 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
* medianfilter
30.7 ms ± 68.2 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Eiger4M.poni
Cython
* integrate
38.2 ms ± 2.31 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
* medianfilter
119 ms ± 867 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Python
* integrate
82.2 ms ± 132 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
* medianfilter
6.9 s ± 29.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
OpenCL
* integrate
2.34 ms ± 3.08 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
* medianfilter
54.2 ms ± 27.4 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Pilatus6M.poni
Cython
* integrate
51.4 ms ± 3.91 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
* medianfilter
156 ms ± 630 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Python
* integrate
103 ms ± 149 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
* medianfilter
10.2 s ± 68.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
OpenCL
* integrate
3.3 ms ± 5.16 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
* medianfilter
78 ms ± 42.9 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Eiger9M.poni
Cython
* integrate
68.6 ms ± 1.41 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
* medianfilter
251 ms ± 1.76 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Python
* integrate
186 ms ± 3.98 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
* medianfilter
16.8 s ± 40.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
OpenCL
* integrate
5.08 ms ± 15.6 μs per loop (mean ± std. dev. of 7 runs, 1 loop each)
* medianfilter
139 ms ± 121 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Mar3450.poni
Cython
* integrate
79.7 ms ± 7.52 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
* medianfilter
265 ms ± 2.82 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Python
* integrate
224 ms ± 983 μs per loop (mean ± std. dev. of 7 runs, 1 loop each)
* medianfilter
19.5 s ± 78.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
OpenCL
* integrate
5.96 ms ± 22.5 μs per loop (mean ± std. dev. of 7 runs, 1 loop each)
* medianfilter
162 ms ± 161 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Fairchild.poni
Cython
* integrate
117 ms ± 5.93 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
* medianfilter
426 ms ± 6.29 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Python
* integrate
306 ms ± 1.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
* medianfilter
23.8 s ± 72.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
OpenCL
* integrate
5.36 ms ± 44 μs per loop (mean ± std. dev. of 7 runs, 1 loop each)
* medianfilter
173 ms ± 164 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
CPU times: user 27min 20s, sys: 22.6 s, total: 27min 43s
Wall time: 13min 51s
fig, ax = subplots()
ax.set_xlabel("Image size (Mpix)")
ax.set_ylabel("Frames per seconds")
sizes = numpy.array(list(perf2_integrate_python.keys()))/1e6
ax.plot(sizes, [1/i.best for i in perf2_integrate_python.values()], label="Integrate/Python", color='green', linestyle='dashed', marker='1')
ax.plot(sizes, [1/i.best for i in perf2_integrate_cython.values()], label="Integrate/Cython", color='orange', linestyle='dashed', marker='1')
ax.plot(sizes, [1/i.best for i in perf2_integrate_opencl.values()], label="Integrate/OpenCL", color='blue', linestyle='dashed', marker='1')
ax.plot(sizes, [1/i.best for i in perf2_medfilt_python.values()], label="Medfilt/Python", color='green', linestyle='dotted', marker='2')
ax.plot(sizes, [1/i.best for i in perf2_medfilt_cython.values()], label="Medfilt/Cython", color='orange', linestyle='dotted', marker='2')
ax.plot(sizes, [1/i.best for i in perf2_medfilt_opencl.values()], label="Medfilt/OpenCL", color='blue', linestyle='dotted', marker='2')
ax.set_yscale("log")
ax.legend()
ax.set_title("Performance of Median filtering vs integrate");
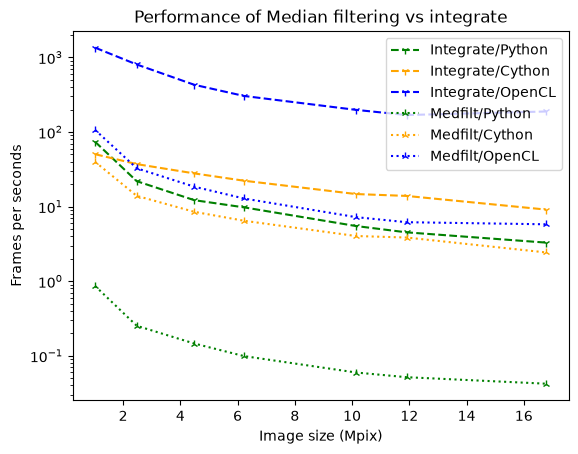
As one can see, the penalties are much larger for OpenCL and Python than for Cython.
Conclusion#
Sigma-clipping and median-filtering are alternatives to azimuthal integration and offer the ability to reject outliers. They are not more difficult to use but slightly slower owing to their greater complexity.